CPU多级缓存
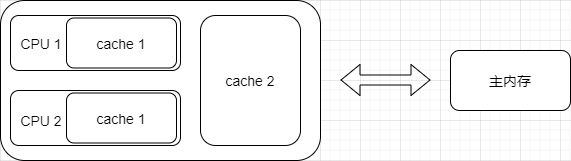
为了解决计算机系统中主内存与CPU之间运行速度差问题,在CPU与主内存之间添加一级或者多级高速缓冲存储器(Cache)。这个Cache一般被集成到CPU内部,所以也叫CPU Cache。
图示为两级Cache结构:
局部性原理
局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
- 时间局部性:如果某个数据被访问,那么在不久的将来它很可能被再次访问
- 空间一致性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问
缓存一致性协议(MESI)
MESI(Modified Exclusive Shared Or Invalid)(也称伊利诺斯协议)是一种广泛使用的支持写回策略的缓存一致性协议。CPU中每个缓存行(Cache line)有4种状态,可用2个bit表示,它们分别是:
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 这行数据无效。 | 无 |
MESI状态转换如图所示:
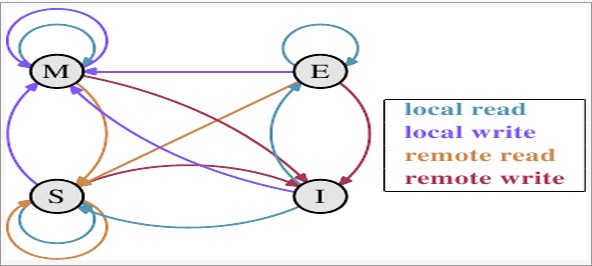
| 事件 | 描述 |
|---|---|
| 本地读取(Local read) | 本内核读本Cache中的值 |
| 本地写入(Local write) | 本内核写本Cache中的值 |
| 远端读取(Remote read) | 其他内核读其他Cache中的值 |
| 远端写入(Remote write) | 其他内核写其他Cache中的值 |
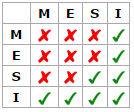
状态之间的相互转换关系也可以使用下表进行表示:
伪共享
什么是伪共享
CPU 访问某个变量时,首先会去看CPU Cache 内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache 行大小的内存复制到Cache 中。
由于存放到Cache 行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache 行中。当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享。
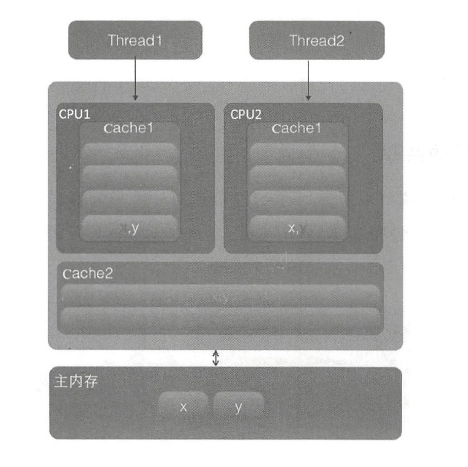
如图所示,变量x 和y 同时被放到了CPU 的一级和二级缓存, 当线程1 使用CPU1 对变量x 进行更新时,首先会修改CPU1 的一级缓存变量x 所在的缓存行,这时候在缓存一致性协议下, CPU2 中变量x 对应的缓存行失效。那么线程2 在写入变量x 时就只能去 二级缓存里查找,这就破坏了一级缓存。而一级缓存比二级缓存更快,这也说明了多个线程不可能同时去修改自己所使用的CPU 中相同缓存行里面的变量。更坏的情况是,如果CPU 只有一级缓存,则会导致频繁地访问主内存。
如何避免伪共享
在JDK 8 之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。
JDK 8 提供了一个sun.misc.Contended 注解(修饰类或变量),用来解决伪共享问题。
在默认情况下,@Contended 注解只用于Java 核心类, 比如rt包下的类。如果用户类路径下的类需要使用这个注解, 则需要添加JVM 参数:-XX:-RestrictContended 。
填充的宽度默认为128 ,要自定义宽度则可以设置 -XX:ContendedPaddingWidth 参数。
Java 指令重排序
Java 内存模型允许编译器和处理器对指令重排序以提高运行性能, 并且只会对不存在数据依赖性的指令重排序。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
数据依赖分为下列3种类型:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a = 1;b = a; | 写一个变量之后,再读这个位置。 |
| 写后写 | a = 1;a = 2; | 写一个变量之后,再写这个变量。 |
| 读后写 | a = b;b = 1; | 读一个变量之后,再写这个变量。 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial 语义
as-if-serial 语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守 as-if-serial 语义。
程序顺序规则
- A happens-before B
- B happens-before C
- A happens-before C
这里的第3个happens-before关系,是根据happens-before的传递性推导出来的。
这里A happens-before B,但实际执行时B却可以排在A之前执行(看上面的重排序后的执行顺序)。如果A happens-before B,JMM并不要求A一定要在B之前执行。JMM仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作A的执行结果不需要对操作B可见;而且重排序操作A和操作B后的执行结果,与操作A和操作B按happens-before顺序执行的结果一致。在这种情况下,JMM会认为这种重排序并不非法,JMM允许这种重排序。
重排序对多线程的影响
1 | int a = 1; // (1) |
上面这段代码中,变量c 的值依赖a 和b 的值,所以重排序后能够保证(3)的操作在(2)(1)之后,但是(1)(2)谁先执行就不一定了,这在单线程下不会存在问题,因为并不影响最终结果。
1 | class ReorderExample { |
这里假设有两个线程 A 和 B,A 首先执行 writer() 方法,随后 B 线程接着执行 reader() 方法。线程 B 在执行操作 (4) 时,实际上不一定能看到线程 A 在操作 (1) 对共享变量 a 的写入。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是 as-if-serial 语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
使用volatile 修饰可以避免重排序和内存可见性问题。写volatile 变量时,可以确保volatile 写之前的操作不会被编译器重排序到volatile 写之后。读volatile 变量时,可以确保volatile 读之后的操作不会被编译器重排序到volatile 读之前。
先行发生(happens-before)规则
happens-before定义
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)。
happens-before规则
- 程序顺序原则:一个线程内保证语义串行性
- volatile规则:volatile变量的写先发生于读
- 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
- 传递性:操作A先于操作B,操作B先于操作C 那么操作A必然先于操作C
- 线程启动规则:线程的start方法先于它的每一个动作
- 线程终止规则:线程的所有操作先于线程的终结(Thread.join())
- 线程中断规则:线程的中断(interrupt())先于被中断的代码
- 对象终结规则:对象的构造函数执行结束先于finalize()方法