概述
消息的消费一般有两种模式:
- 推模式:服务端主动将消息推送给消费者。
- 拉模式:消费者主动从服务端拉取消息。
Kafka中的消费是拉模式,消费者轮训订阅的主题/分区进行消息拉取,支持订阅一个或多个主题,同时也支持订阅分区。
代码示例
1 | public class KafkaConsumerTest { |
消费者与消费组
消费者订阅Kafka中的主题并且拉取消息。每个消费者都对应一个消费组,当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。
Kafka支持两种消息投递模式:
- 点对点模式:所有消费者隶属于同一个消费组。此时所有消息会被均衡地投递给每一个消费者,即每条消息只会被一个消费者处理。
- 发布/订阅模式:所有的消费者都隶属于不同的消费组。此时所有的消息都会被广播给所有的消费者,即每条消息都会被所有的消费者处理。
分区分配策略
KafkaConsumer可以通过参数partition.assignment.strategy设置消费者与订阅主题之间的分区分配策略,可配置为多个分配策略。默认情况值为org.apache.kafka.clients.consumer.RangeAssignor,即使用RangeAssignor分配策略。Kafka还支持RoundRobinAssignor和StickyAssignor两种分配策略,
RangeAssignor分配策略(默认)
此策略分配原理是按照消费者总数和分区总数进行整除获得跨度,然后将分区按照跨度进行平均分配。
对于每一个主题,RangeAssignor策略会将消费组内所有订阅主题的消费者按照名称排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,则顺序靠前的消费者会被多分配一个分区。
例如,消费组中有两个消费者C0和C1,都订阅了主题T0和T1,每个主题都有3个分区,即T0P0/T0P1/T0P2、T1P0/T1P1/T1P2。最终的分配结果为:
- 消费者C0:T0P0、T0P1、T1P0、T1P1
- 消费者C1:T0P2、T1P2
RangeAssignor策略存在分配不均的情况,极端情况下可能出现部分消费者过载。
RoundRobinAssignor分配策略
此策略分配原理是将消费组内所有的消费者以及消费者订阅的所有主题分区排序,然后通过轮训的方式将分区以此分配给每个消费者。
例如,消费组中有两个消费者C0和C1,都订阅了主题T0和T1,每个主题都有3个分区,即T0P0/T0P1/T0P2、T1P0/T1P1/T1P2。最终的分配结果为:
- 消费者C0:T0P0、T0P2、T1P1
- 消费者C1:T0P1、T1P0、T1P2
如果同一个消费组内的消费者订阅的信息不同,那么在分区分配时就不是完全的轮训分配,也有可能导致分配不均。
例如,消费组中有三个消费者C0、C1、C2,共订阅了主题T0、T1、T2,分别有1、2、3个分区,即T0P0、T1P0/T1P1、T2P0/T2P1/T2P2。C0订阅T0,C1订阅T0和T1,C2订阅T1和T2,则最终的分配结果为:
- 消费者C0:T0P0
- 消费者C1:T1P0
- 消费者C2:T1P1、T2P0、T2P1、T2P2
StickyAssignor分配策略
SkickyAssignor分配策略有两个目的:
- 分区的分配尽可能均匀
- 分区的分配尽可能与上次分配的保持相同
当两者发生冲突时第一个目标优先于第二个目标。
例如,消费组中有两个消费者C0、C1、C2,都订阅了主题T0、T1、T2、T3,每个主题都有2个分区,即T0P0/T0P1、T1P0/T1P1、T2P0/T2P1、T3P0/T3P1。最终的分配结果为:
- 消费者C0:T0P0、T1P1、T3P0
- 消费者C1:T0P1、T2P0、T3P1
- 消费者C2:T1P0、T2P1
在以上分配完成后,如果C1脱离了消费组,那么消费组就会进行再均衡重新分配分区,此时如果使用RoundRobinAssignor分配策略结果为:
- 消费者C0:T0P0、T1P0、T2P0、T3P0
- 消费者C2:T0P1、T1P1、T2P1、T3P1
如上所示,RoundRobinAssignor分配策略会按照CO和C2进行重新轮训分配。但是如果使用SkickyAssignor分配策略会保留上次的分配结果,在此基础上对C1被分配的分区重新分配,再分配结果为:
- 消费者C0:T0P0、T1P1、T3P0、T2P0
- 消费者C2:T1P0、T2P1、T0P1、T3P1
对于前文提到的RoundRobinAssignor无法分配不均的情况,消费组中有三个消费者C0、C1、C2,共订阅了主题T0、T1、T2,分别有1、2、3个分区,即T0P0、T1P0/T1P1、T2P0/T2P1/T2P2。C0订阅T0,C1订阅T0和T1,C2订阅T1和T2,StickyAssignor分配策略最终的分配结果为:
- 消费者C0:T0P0
- 消费者C1:T1P0、T1P1
- 消费者C2:T2P0、T2P1、T2P2
消费位移
在Kafka分区中每条消息都有唯一的offset用来表示消息在分区中的位置。对于消费者而言,也有offset的概念,用来表示消费到分区中消息的位置,可以称为是消费位移。
在新的客户端中,消费位移存储在Kafka内部的主题__consumer_offsets中。在消费完消息之后,消费者需要进行消费位移的提交。如下图所示,当前拉取消息的起始位置是上一次提交的消费位移,而本次将要提交的消费位置是拉取到的最大位移+1。
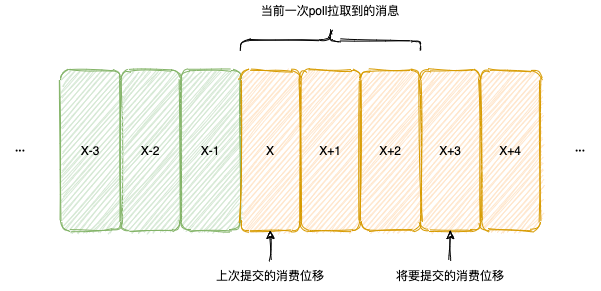
__consumer_offsets主题在Kafka集群第一次有消费者消费消息时自动创建,副本数由offsets.topic.replication.factor参数设置,默认3,分区数由offsets.topic.num.partitions参数设置,默认50。
位移提交
Kafka中的消费位移提交支持两种方式:
- 自动提交(默认):默认情况下每隔5s会将拉取到的每个分区中的最大消息位移进行提交。此方式可能会导致重复消费和消息丢失。
- enable.auto.commit:自动提交开关,默认true
- auto.commit.interval.ms:定期提交周期,默认5s
- 手动提交:可细分为同步提交和异步提交两种方式。
指定位移消费
当一个消费组建立的时候或者消费组中的一个新的消费者订阅了一个新的主题,又或者__consumer_offsets主题中有关这个消费组的位移消息过期而被删除时,Kafka中的消费者查找不到记录的消费位移。
此时会根据消费者客户端参数auto.offset.reset参数配置来决定从何处开始进行消费,可选参数如下:
- latest:从分区末尾开始消费消息(默认)
- earliest:从分区起始开始消费消息
- none:抛出异常
KafkaConsumer支持使用seek()方法从特定位移处开始拉取消息,需要注意的是,在执行seek()方法前需要先执行poll(),在分配到分区之后才可以重置消费位置。
再均衡
当添加或删除消费组中的消费者时会发生再均衡,即分区的所属权从一个消费者转移到另一个消费者。在再均衡发生期间,消费组不可用,同时当一个分区被重新分配给另一个消费者是,消费者当前状态也会丢失。比如,消费者消费完某个分区中的一部分消息还没来得及提交消息位移就发生了再均衡操作,之后这个分区被分配给了消费组中的另一个消费者,此时消息就会被重复消费。所以应该尽量避免不必要的再均衡发生。
重要参数
- group.id:消费组名称
- fetch.min.bytes:一次拉取请求能拉取的最小数据量,默认1B
- fetch.max.bytes:一次拉取请求能拉取的最大数据量,默认50M
- fetch.max.wait.ms:等待时间,默认500ms
- max.partition.fetch.bytes:每个分区返回给消费者的最大数据量,默认1M
- max.poll.records:一次请求拉取的最大消息数,默认500条
- connections.max.idle.ms:连接最长空闲时间,默认9min
- exclude.internal.topics:指定内部主题(__consumer_offsets、__transaction_state)是否对消费者公开,默认true
- receive.buffer.bytes:Socket接收缓冲区大小,默认64K
- send.buffer.bytes:Socket发送消息缓冲区大小,默认128K
- request.timeout.ms:消费者请求最长等待时间,默认30s
- metadata.max.age.ms:元数据过期时间,默认5min
- reconnect.backoff.ms:重连等待时间,默认50ms
- retry.backoff.ms:重试间隔时间,默认100ms