Paxos、Raft、ZAB等分布式算法常被称为“强一致性”的分布式共识协议,其意思是尽管系统内部节点可以存在不一致的状态,但是从系统外部看,不一致情况不会被观测到,所以整体上看系统是强一致的。相对的,还有一类“最终一致”的分布式共识协议,表示系统中的不一致状态有可能会在一定时间内被外部观测到。
最终一致分布式共识协议的一个典型就是DNS协议,在各个节点缓存的ttl过期前是有可能与真实域名翻译结果不一致的情况。另一种具有代表性的则是在比特币网络和许多分布式系统中都有应用的Gossip协议。
Gossip协议源于施乐公司在论文中提出的一种用于分布式数据库在多节点间复制同步数据的算法,其特点是要同步的消息像流言一样传播、病毒一样扩散,因为也被称为“流言算法”、“瘟疫算法”等。
算法流程
Gossip算法的工作流程十分简单,如果有某一项信息需要在整个网络所有节点中传播可以看做是以下两个步骤的简单循环:
- 从信息源开始,选择一个固定的传播周期(譬如1秒),随机选择与它相连的k个节点(称为Fan-Out)来传播消息。
- 每一个节点收到消息后,如果这个消息是它没收到过的,在下一个周期内,将在会在除发消息的节点外的其他相邻节点中选择k个发送相同的消息,直到最终网络中所有节点都收到了消息。
尽管以上流程需要一定的时间,但是理论上最终网络中所有节点都会拥有相同的信息。
算法流程示意图如下所示:
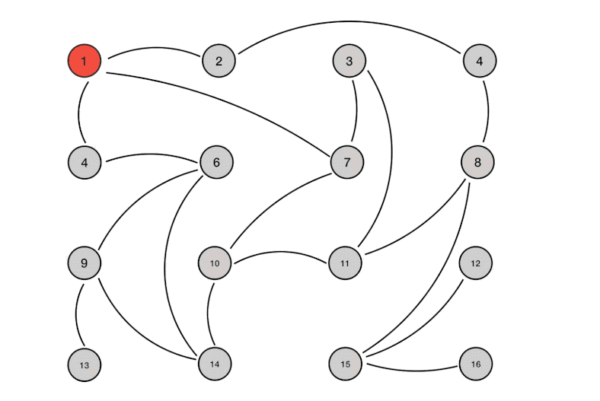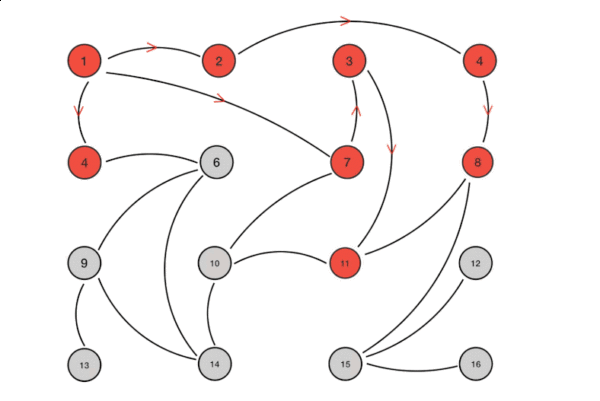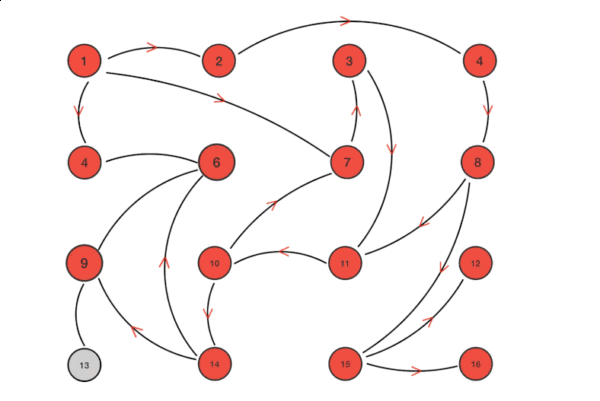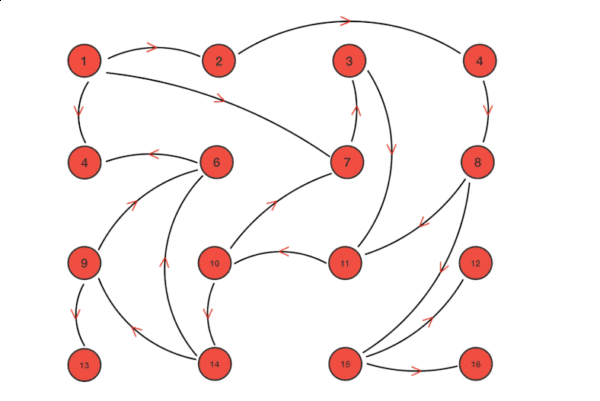
从上图中我们可以看到Gossip协议对网络节点的连通性和稳定性几乎没有任何要求。Gossip将网络某些节点中能与部分节点连通而不是全网络节点连通作为前提,能够容忍网络上节点的随意增加或者减少、随意宕机或者重启,新增或者重启的节点最终会与其他节点同步达成一致。Gossip把网络中的节点平等看待,没有中心化或者主节点的概念,正因如此,Gossip具有极强的鲁棒性,非常适合在公众网络中使用。
Gossip的缺点也是显而易见的:
- 消息是经过多个轮次的散播到达网络中所有节点的,必然存在各个节点状态不一致的情况。
- 由于随机选择发送消息的节点,所以尽管可以在整体上测算出统计学意义上的传播速率,但是对于个体消息而言,无法准确地预计需要多长时间才能达到全网一致。
- 由于随机选择发送消息的节点,不可避免的存在重复消息发送给同一个节点的情况,消息冗余带来的是网络传输的压力,也给消息节点带来额外的负载。
达到一致性耗费的时间与网络传输中消息冗余这两个缺点对立,鱼与熊掌不能兼得,因此,Gossip设计了两种可能的消息传播模式:
- 反熵模式,同步的所有数据以消除各个节点之间的差异,目标是整个网络各个节点完全一致,但是在节点本身就会发生变动的前提下,这个目标会使得整个网络中消息的数量非常庞大。
- 传谣模式,以传播消息为目标,仅仅发送新达到节点的数据,即只对外发送变更数据,此模式下消息数据量将会显著减少,网络开销也相对较小。