G1垃圾回收器(垃圾优先回收器):
- 垃圾回收优先,优先回收垃圾,不会等到空间全部占满然后进行回收
- 停顿预测模型,预测一次回收可以回收的分区数量,以满足对停顿时间的要求
- 化整为零的分区机制,内存分为n个大小相同的分区(Region),这种灵活可变的Region机制是G1控制停顿时间的核心设计
G1内存模型:HeapRegion是G1垃圾回收器内存管理的基本单位,也是最小单位。
分区类型:
- 新生代分区:Young Heap Region YHR
- 自由分区:Free Heap Region FHR
- 老年代分区:Old Heap Region OHR
- 大对象分区:Humongous Heap Region HHR
ParNew+CMS与G1内存模型对比:
- ParNew+CMS,新生代(Eden、Survivor1、Survivor2)、老年代
- 优势:管理简单,小内存时垃圾回收不会造成很大的停顿
- 劣势:大内存停顿时间长,例如分配64G给JVM,Eden区20-30G,回收一次Eden区可能需要2-3s
HeapRegion
G1如何设置HeapRegion大小:
- 手动式,通过参数 G1HeapRegionSize 设置,默认为0,范围限制为1-32MB,需要是2的n次方
- 启发式判断,G1根据内存(堆内存大小、分区数)自动计算
HeapRegion大小对垃圾回收的影响:
- Region过小
- 找可以使用的Region难度增加
- 跨区存储概率增加
- Region过大
- Region回收价值判断麻烦
- 回收判定过程复杂,标记对象时对象多引用多、遇到跨代跨区存储还需要额外处理
Region大小计算:
- 计算公式:
region_size = max((InitialHeapSize+MaxHeapSize)/2/2048,1MB),范围[1,32]MB- 堆分区个数默认为2048,这个数字会根据具体内存大小自动计算,不能手动指定分区个数
- 堆内存大小默认最大96MB(MaxHeapSize,+Xmx),最小0MB(InitialHeapSize,+Xms)
- e.g.
- 只指定Region大小,设置Region大小为2MB,则G1总内存为2024*2MB=4GB,分区数2048
- 指定堆内存且最大值等于最小值,设置堆内存Xms=Xmx=32GB,则RegionSize=max((32GB+32GB)/2/2048,1MB)=16MB
- 指定堆内存且最大值不等于最小值,Xms=32GB,Xmx=128GB,则RegionSize=max((32GB+128GB)/2/2048,1MB)=32MB,G1会自动计算分区个数,分区范围在32GB/32MB=1024 ~ 128GB/32GB=4096之间
- 如果RegionSize不符合规则,G1会自动和2^n对齐,找数字里包含的最大的2的n次幂
内存扩展机制
新生代内存分配方式:
- 参数指定方式
- 指定新生代大小,设置MaxNewSize、NewSize,设置Xmn相等于同时设置Xmn=MaxNewSize=NewSize
- 指定新生代比例,NewRatio,只设置NewRatio时MaxNewSize=NewSize=heapSize/(NewRatio+1),如果同时设置MaxNewSize、NewSize、NewRatio则NewRatio会被忽略
- G1启发式推断
- 没有指定MaxNewSize、NewSize,或只设置其中一个,则G1会根据G1MaxNewSizePercent(默认60%)和G1NewSizePercent(默认5%)配置计算初始化和最大新生代大小
一般来说,在使用G1垃圾回收器时,不推荐自己指定新生代大小,而是让G1自动推断。除非是经过长时间观察找到了一个合理的新生代范围(MaxNewSize!=NewSize)。G1的新生代动态扩展可以帮助动态调整YGC所需时间。
G1扩展新分区时机&规则:
- 参数GCTimeRatio设置GC与应用耗时时间比,默认值9,如果GC时间占比超过10%则需要进行动态扩展
- 参数G1ExpandByPercentOfAvailable设置每次扩展从未使用内存中申请比例,默认值20,并且最小1MB,最大为已使用内存大小
内存扩展流程:
- 新生代不足 -> 新生代扩展 -> 找自由分区 -> 自由分区不足 -> 从堆内存申请新分区 -> 加入新生代分区列表
- 后台线程抽样 -> GC时间占比超过10% -> 自动扩展新生代分区 -> 找自由分区 -> 自由分区不足 -> 从堆内存申请新分区 -> 加入新生代分区列表
停顿预测模型
G1中的停顿预测模型为衰减标准差算法,公式如下:
1 | davg(n) = Vn,n=1 |
α为衰减因子,是一个小于1的固定值,值越小,最新GC数据对结果影响越大。
例如α=0.6,GC次数为3,第一次回收2GB用时200ms,第二次回收5GB用时300ms,第三次回收了3GB用时500ms,那么计算结果如下:
davg(1)=2GB/200ms
davg(2)=(1-0.6)*5GB/300ms + 0.6*2GB/200ms
davg(3)=(1-0.6)*3GB/500ms + 0.6*((1-0.6)*5GB/300ms + 0.6*2GB/200ms)
从davg(3)中可以看出,权重最大的就是最后一次GC。
基于衰减算法模型的垃圾回收过程:
- 获取历史GC数据
- 使用衰减平均值算法模型计算衰减平均值,评估垃圾回收能力
- 根据目标停顿时间和当前回收能力选择一定数量的Region
- 执行垃圾回收
对象分配
G1中使用TLAB(Thread Local Allocation Buffer)机制来进行对象分配,即每个线程都一个自己的本地分配缓冲区,专门用于对象的快速分配。
使用TLAB机制只需要在线程创建时对堆内存加锁,减少了锁冲突导致的串行化执行问题,实现了对象分配时的无锁化。
TLAB原理
TLAB过小,会导致TLAB被快速填满,从而导致对象不走TLAB分配,效率会变差。TLAB过大会造成内存碎片,拖慢回收效率。
TLAB在初始化时大小通过公式计算:TLABSize = Eden * 2 * 1% / 线程数。
G1中如果TLAB满了,有两种方式分配:
- 重新申请一个TLAB给当前线程
- 直接通过堆内存分配对象
G1中存在一个refill_waste值,在JVM虚拟机内部维护,表示一个TLAB可以浪费的内存大小。也就是说,一个TLAB中最多可以剩余refill_waste空闲空间就可以认为TLAB满了。refill_waste可以通过TLABRefillWasteFraction调整,表示TLAB可以浪费的比例,默认值64,即可以浪费1/64。
分配对象空间不足时处理流程:
- 对象所需空间大于refill_waste,则直接在TLAB外分配(这个过程不同的GC算法有不同的规则),也就是在堆内存直接分配。
- 对象所需空间小于refill_waste,则重新申请一个TLAB,用来存储新创建的对象,重新申请时会动态调整refill_waste和TLAB大小,以适应当前系统分配对象的情况。
- 如果申请TLAB失败,则进入堆加锁分配,失败则尝试扩展分区,申请Region失败则走垃圾回收(YoungGC,MixedGC),垃圾回收次数超过阈值则进行最终尝试,失败直接结束并OOM。
最终分配尝试流程:
- 第一次FullGC,不回收软引用,完成后尝试分配对象,成功则结束,不成功进行第二次GC
- 第二次FullGC,回收软引用,完成后尝试分配对象,成功则结束,不成功则OOM
TLAB通过指针碰撞法来判断是否有可用的连续内存,top指针指向空闲内存开始位置,end指针指向整个TLAB结束位置,在分配对象时判断待分配对象空间和剩余空间大小(end - top)关系即可。
TLAB长度固定,有可能会产生无法使用的内存空间,这些内存碎片由虚拟对象进行填充。
TLABSize最大值为RegionSize/2,大对象>TLABSize直接走慢速分配,到大对象分区分配。大对象在分配时,会判断是否启动垃圾回收和并发标记。
核心机制
记忆集RememberSet
记忆集是一组K-V结构,记录跨代引用关系,在GC时,可以借助记忆集和GCRoots快速解决同代引用及跨代引用的可达性分析问题,避免每次都将堆中所有对象都标记一遍。
G1中的记忆集是以Region为最小内存管理维度,存储Region里所有对象被引用的引用关系,K为引用方对象所在Region地址,V为数组,存放引用方对象所在卡页在卡表中的下标。
G1记忆集中记录的引用关系类型:
- 老年代Region到新生代Region的引用关系,用来解决新生代回收时跨代引用
- 老年代Region到老年代Region的引用关系,用来解决混合回收老年代选择部分Region回收时引用
位图BitMap
G1中使用位图来描述内存使用状态,主要是在混合回收的并发标记阶段,用来提升内存是否使用的判定效率。
卡表CardTable
G1中使用全局卡表来描述整个堆的内存使用情况,本质上与位图类似,区别是描述内容比位图更多。卡表用一个字节来描述512字节的内存使用情况,以及垃圾回收过程中的状态信息。
G1使用记忆集+卡表来解决分代模型中跨代引用关系判定和追踪问题。记忆集+卡表机制在时间和空间上做了平衡,在找老年代引用对象时,实际上就是遍历对应卡页的内存,按照对象长度的内存空间为步长遍历整体性能不会很差。
DCQ机制
G1通过DCQ(Dirty Card Queue)脏数据队列来更新RSet,当引用关系发生变更时,发送变更消息到DCQ,Refine线程异步消费并更新RSet。
Refine线程最大线程数为G1ConcRefinementThreads+1,每个线程都关联一个DCQ,每个DCQ长度为256,当DCQ写满就申请一个新的DCQ并把老的DCQ提交到DCQ Set里,即二级缓存DCQS。当DCQS不能存放更多的DCQ时,会由工作线程处理这个DCQ。
G1给每个变更屏障操作前加了一个写屏障,用来增强操作,主要作用为:
- 过滤掉不需要写的引用变更操作,比如新生代到新生代的引用、同一个Region的引用等
- 把正常的变更数据写入一条到DCQ里
G1给DCQS做了四个区域,由参数G1ConcRefinementGreenZone、G1ConcRefinementYellowZone、G1ConcRefinementRedZone划分,默认都是0,如果没有设置则由G1自动推断。四个区域如下:
- 白区,[0,green),不启动Refine线程处理DCQ
- 绿区,[green,yellow),根据DCQS元素个数来计算启动Refine线程个数
- 黄区,[yellow,red),所有Refine线程都参与到DCQ处理
- 红区,[red,正无穷),所有Refine线程以及系统工作线程都参与DCQ处理
垃圾回收
G1回收器相关参数:
- -XX:+UseG1GC,使用G1垃圾回收器
- -XX:G1HeapRegionSize,Region分区大小,最小值1MB,最大值32MB,且只能是2的n次幂
- -Xms -Xmx,堆内存最大值最小值
- -XX:NewSize -XX:MaxNewSize,新生代最小值和最大值,这个最大值最小值在G1里一般不需要设置,G1会自动计算出来一个值,从5%的Region数量开始,最大为60%
- -XX:G1NewSizePercent -XX:G1MaxNewSizePercent,新生代region数量下限,默认5%-60%
- -XX:SurvivorRatio,新生代Eden和Survivor的比例,默认8,即eden:s1:s2=8:1:1
- -XX:MaxGCPauseMills,最大GC暂停时间。这是一个大概值,JVM会尽可能的满足此值
- -XX:NewRatio,new/old代的大小比例,默认2,只设置一个NewRatio和只设置一个Xmn相当
- -XX:ParallelGCThreads,参与回收的线程数量,默认和CPU核数相等
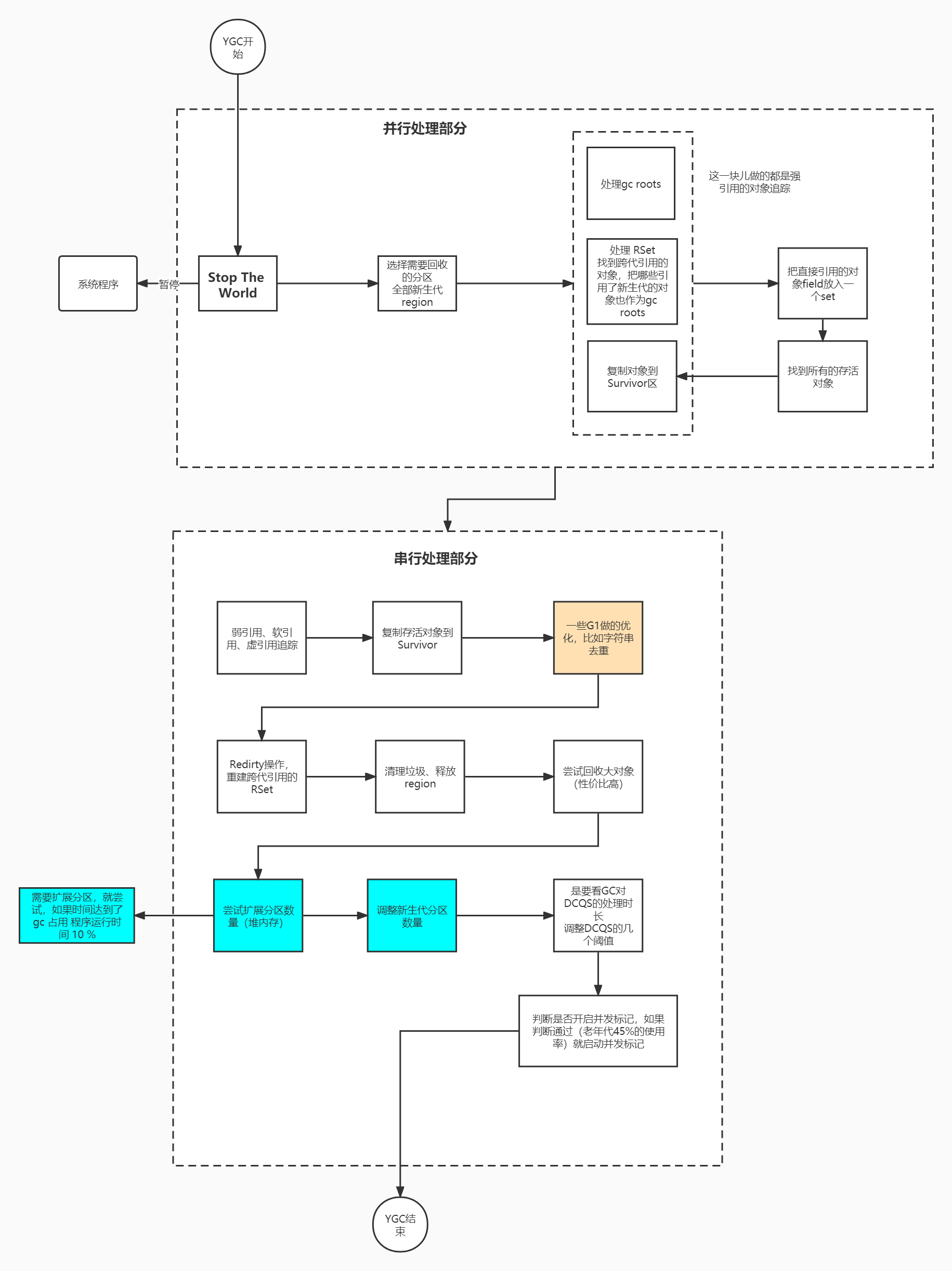
YoungGC
YoungGC流程:
- 从GCRoot触发标记存活对象
- 暂停Refine线程,由GC线程消费DCQS并更新RSet,把RSet也作为GCRoot执行对象标记
- 把GCRoot+RSet直接引用的对象所有field放到栈里,遍历栈,直到找到所有存活对象
- 复制存活对象到Survivor区
- 回收垃圾对象
- 整理卡表
- 重构RSet
- 释放分区
- 尝试回收大对象
- 动态调整新生代Region数量
- GCTimeRatio+G1ExpandByPercentOfAvailable参数,GC时间占比超过10%就需要扩展新生代内存
- 调整新生代分区数量和Refinement Zone阈值
- 判断是否需要开启并发标记
- 老年代内存使用率达到45%,在YGC结束后开启并发标记
MixedGC
MixedGC流程:
- 初始标记,Stop The World,伴随一次YGC,YGC结束时会判断是否需要开启并发标记
- 并发标记
- 起始对象:Survivor区存活对象+GCRoots引用的老年代对象+RSet
- 使用位图+三色标记法标记对象是否存活,黑色-存活,灰色-存活但子对象未遍历完全,白色-死亡
- SATB(Snapshot-At-The-Beginning)对象引用的快照状态,通过写屏蔽放入到SATB队列用来记录工作线程造成的引用变化
- 最终标记,STW,针对并发标记阶段由于系统运行造成的错标漏标情况进行修正,本质上是把SATB队列里的对象重新标记
- 预回收阶段
- 根据RSet+BitMap完成存活对象的统计工作,按结果给Region排序
- 更新prevBitMap位图,为下一次并发标记做准备(如果回收成功,则忽略)
- 重置RSet,如果标记后分区没有对象被引用则删除旧的引用关系
- 清理全部都是垃圾的分区
- 混合回收阶段
- 选择一些分区(Collect Set)进行回收,把分区内存活对象复制到空闲分区,清理原分区
- Collect Set算法依据回收性价比,单位时间内能回收的垃圾越多性价比越高,回收能力看对象转移效率,也就是存活对象越少性价比越高
- G1MixedGCLiveThresholdPercent,如果一个分区存活对象达到默认85%就不加入到CSet
- G1HeapWastePercent,如果选择的CSet可以回收的垃圾占总堆5%才会开始回收,否则不回收
- G1MixedGCCountTarget,最多分8次完成回收,每回收一次都再次判断G1HeapWastePercent
- G1OldCSetRegionThresholdPercent,每次回收掉的分区数不能超过整个堆分区数量的10%
FullGC
FullGC流程(STW):
0. 前置处理,保存对象头、锁等信息
- 标记存活对象,分区并行+任务窃取提高性能
- 计算对象的新地址,单个线程处理的多个Region存活对象压缩到同一个Region
- 更新引用对象的地址
- 移动对象完成压缩(复制覆盖操作)
- 复制后的处理
- 尝试调整整个堆分区的数量大小
- 遍历整个堆,重构RSet
- 清除dirty card队列,更新卡表,把所有分区设置为Old分区
- 记录GC信息,更新新生代大小,选择一些分区作为新生代,重新构建Eden
补充:G1新特性,字符串去重优化,筛选条件:
- 如果在YGC阶段
- 当字符串需要复制到S区,根据年龄判断达到阈值StringDeduplicationAgeThreshold则参与去重
- 当字符串需要晋升到Old区,并且对象年龄小于阈值StringDeduplicationAgeThreshold则参与去重
- 如果在FullGC阶段,只需判断字符串对象是否年龄小于阈值,因为完成GC后所有分区都会被标记为Old分区
找到所有需要去重的字符串后,会把这些字符串放到一个队列,开启一个后台线程利用HashTable结构完成去重操作。官方数据,经过去重操作能够节省约13%的内存,提升明显。